DAIKIN ダイキン セラムヒート CER11WS-W
(税込) 送料込み
商品の説明
DAIKIN ダイキン セラムヒート CER11WS-W
遠赤外線暖房機 タイマー付
2019年製
本体のみです。
動作確認済み。
首振りもしっかり動きます。
多少の使用感や細かなスレ等ありますが、
状態は良いと思います。
リサイクル段ボールに梱包して発送予定です。
よろしくお願いします。
30116011000
遠赤外線暖房機 セラムヒート
CER11WS-W (マットホワイト)
ブランド:ダイキン セラムヒート
電気ストーブ種類:シーズヒーター
消費電力(W):1100.0 W
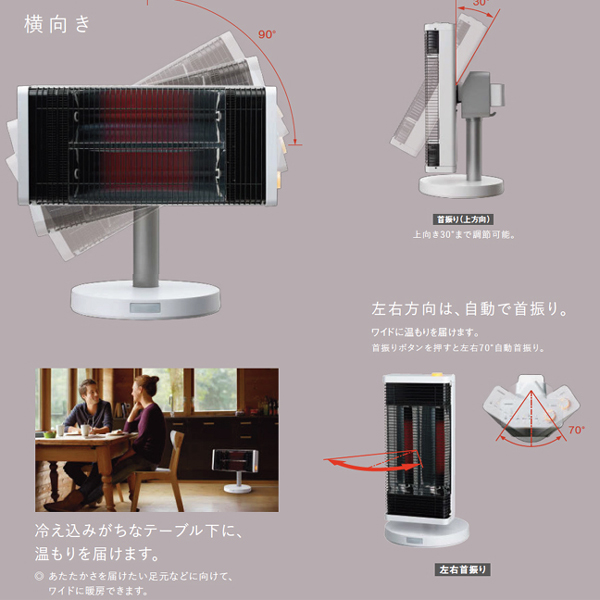
電気ストーブ機能:風量調節 首振り タイマー
安全機能:チャイルドロック 転倒時自動電源遮断装置
コード長さ(m):2.0 m
幅(mm):342.0 mm
奥行き(mm):342.0 mm
高さ(mm):652.0 mm
色:ホワイト系商品の情報
| カテゴリー | 家電・スマホ・カメラ > 冷暖房/空調 > 電気ヒーター |
|---|---|
| 商品の状態 | やや傷や汚れあり |

国産お得 DAIKIN CER11WS-W ダイキン セラムヒート Msudi-m32223280337

DAIKIN ダイキン セラムヒート CER11WS-W | video.aacntv.com

国産お得 DAIKIN CER11WS-W ダイキン セラムヒート Msudi-m32223280337

正式的 DAIKIN ダイキン セラムヒート CER11WS-W 2019年製 美品 電気

国産お得 DAIKIN CER11WS-W ダイキン セラムヒート Msudi-m32223280337

DAIKIN ダイキン セラムヒート CER11WS-W | video.aacntv.com

DAIKIN(ダイキン)セラムヒート「CER11WS-W」入荷いたしました

DAIKIN ダイキン セラムヒート CER11WS-W | video.aacntv.com
ダイキン CERAMHEAT 遠赤外線暖房機 セラムヒート CER11WS-W 2020年

大特価!! DAIKIN CER11WS-W 2019年製 セラムヒート 遠赤外線 ダイキン

DAIKIN ダイキン セラムヒート CER11WS-W | video.aacntv.com

DAIKIN ダイキン セラムヒート CER11WS-W www.krzysztofbialy.com

クリアランス販売店 DAIKIN ダイキン セラムヒート CER11WS-W 電気

DAIKIN ダイキン セラムヒート CER11WS-W www.krzysztofbialy.com

DAIKIN ダイキン セラムヒート CER11WS-W www.krzysztofbialy.com

純正直売 ☆ダイキン 遠赤外線暖房機 セラムヒート CER11YS-W 遠赤外線

楽天市場】<在庫あります>CER11YS-W ダイキン 遠赤外線ストーブ

正式的 DAIKIN ダイキン セラムヒート CER11WS-W 2019年製 美品 電気

DAIKIN ダイキン セラムヒート CER11WS-W www.krzysztofbialy.com

DAIKIN ダイキン セラムヒート CER11WS-W www.krzysztofbialy.com
クリアランス販売店 DAIKIN ダイキン セラムヒート CER11WS-W 電気

正式的 DAIKIN ダイキン セラムヒート CER11WS-W 2019年製 美品 電気

遠赤外線暖房機 セラムヒート 特長 (ぴちょんくんのお店取扱製品

クリアランス販売店 DAIKIN ダイキン セラムヒート CER11WS-W 電気

DAIKIN ダイキン セラムヒート CER11WS-W - 通販 - pinehotel.info

□DAIKIN/ダイキン□セラムヒート□遠赤外線暖房機□人感センサー

パーティを彩るご馳走や CERAMHEAT セラムヒート ダイキン 岩)DAIKIN

ダイキン セラムヒート CER11VS-W-

クリアランス販売店 DAIKIN ダイキン セラムヒート CER11WS-W 電気

DAIKIN ダイキン セラムヒート CER11WS-W | video.aacntv.com
楽天市場】ダイキン DAIKIN ダイキンセラムヒート CERAMHEAT CER11YS-W

□DAIKIN/ダイキン□セラムヒート□遠赤外線暖房機□人感センサー

クリアランス販売店 DAIKIN ダイキン セラムヒート CER11WS-W 電気

格安販売中 ダイキン セラムヒート CER11WS 遠赤外線暖房機 電気

ダイキン CER11WS-W 遠赤外線暖房機 セラムヒート ダイキン (DAIKIN

通販HOT ☆〓DAIKIN / ダイキン 遠赤外線暖房機 セラムヒート CER11WS

クリアランス販売店 DAIKIN ダイキン セラムヒート CER11WS-W 電気

DAIKIN ダイキン セラムヒート CER11WS-W|PayPayフリマ

DAIKIN(ダイキン)セラムヒート「CER11WS-W」入荷いたしました

ダイキン DAIKIN 遠赤外線暖房機 セラムヒート CERAMHEAT マット








商品の情報
メルカリ安心への取り組み
お金は事務局に支払われ、評価後に振り込まれます
出品者
スピード発送
この出品者は平均24時間以内に発送しています














